An unsupervised neural network that learns to map an input to a latent representation and then reconstruct it back as
Architecture Components:
- Encoder : Maps input to a code
- Decoder : Maps code back to reconstruction
- Bottleneck: A hidden layer where , forcing the network to compromise information.
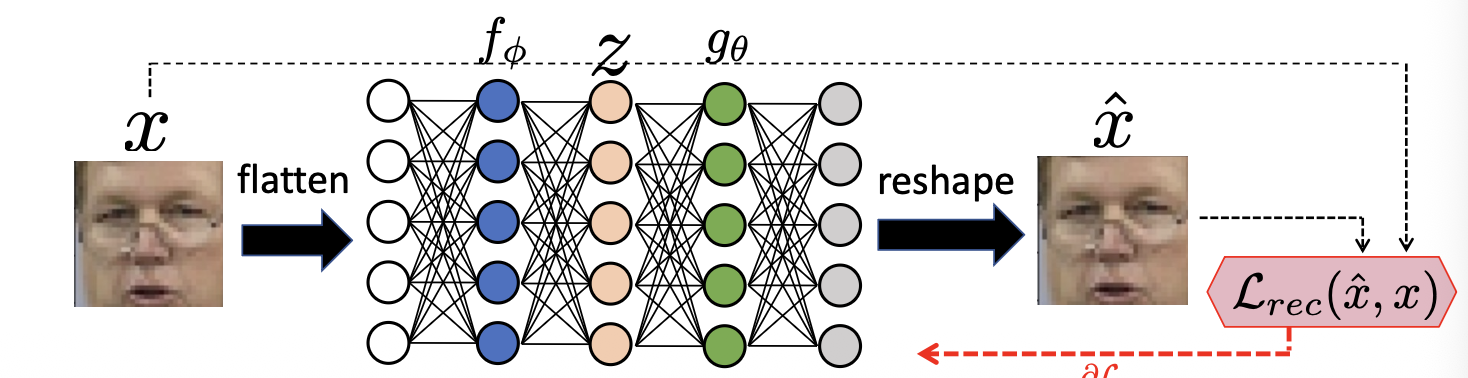
Loss Function
Uses Mean Squared Error (MSE), also known as Reconstruction Loss . It penalises wrong pixel intensities by calculating the average squared difference between original pixels and reconstructed pixels .
Global Optimum
The loss is minimised when the reconstruction perfectly matches the input .
The Bottleneck and Trivial Solutions
- The “Identity Function” Problem: If an Auto-Encoder has no constraints, it may learn a trivial solution (a useless function) where it simply copies the input to the output without learning any meaningful features.
- The Bottleneck Solution: By making the hidden layer smaller than the input, the Auto-Encoder is forced to learn the most prominent/important features of the data.
- Features Trade-offs:
- Wider Bottlenecks: Better reconstruction but less compression; might learn “lower level” features (like individual pixels).
- Narrower Bottleneck: Forces “high level” features (e.g., skin colour, location of eyes, hair type) but might loose fine details like glasses.
- Visual Inspection: Since we don’t control which features are learned, we can investigate them by encoding an input , slightly changing one value in the code , and decoding it to see what changed in the reconstruction.
Application: Video Streaming
- A company trains an Auto-Encoder on movie frames.
- They store only the compressed code (e.g., 512 values instead of 921,600 pixels).
- The customer downloads the decoder and receive only the small codes , reconstructing the frames locally for fast streaming.
Unsupervised Clustering
- Auto-Encoders learn to map similar samples close together in the latent space and different samples far apart.
- Logic: If the encoder mapped two different digits to the same , the decoder would fail to reconstruct them correctly, resulting in high loss. Therefore, successful reconstruction requires to be well-clustered.
Semi-Supervised Learning with Auto-Encoders
- Goal: Train a classifier when labelled data is very small.
- Process:
- Pre-train an Auto-Encoder on a large amount of unlabelled data to learn a robust encoder
- Discard the decoder
- Attach a shallow classifier (1-2 layers) on top of the trained encoder.
- Two approaches for the Classifier Phase:
- Frozen Encoder: Train only the classifier after using limited labels.
- Advantage: Prevents overfitting
- Disadvantage: Encoder isn’t optimised for the specific labels.
- Fine-tuning: Train both encoder and classifier for a few iterations
- Advantage: Potential for better representation.
- Disadvantage: High risk of overfitting; requires careful validation.
- Frozen Encoder: Train only the classifier after using limited labels.