Mechanics of Convolutional
A convolutional layer slides a kernel (a mix of weights) over an image to compute dot product, which are then followed by a bias and an activation function.
- Kernel Effect: Depending on its values, a kernel can perform identity, edge detection, sharpening or blurring (Box, blur, Gaussian blur).
- Geometric Interpretation: A dot product with a kernel gives the signed distance to a hyperplane defined by .
- Spatial Dimensions: Convolution typically makes the output matrix smaller than the input unless padding is used.
Padding, Stride and Output Size
- Stride: The step size the filter takes as it slides across the image. A stride of reduces the output size significantly.
- Padding: Zero-padding (“Same” convolution) adds zeros around the border to keep the output size the same as input.
- Magic Formula: To calculate the output width () for an input , kernel size , padding , and stride :
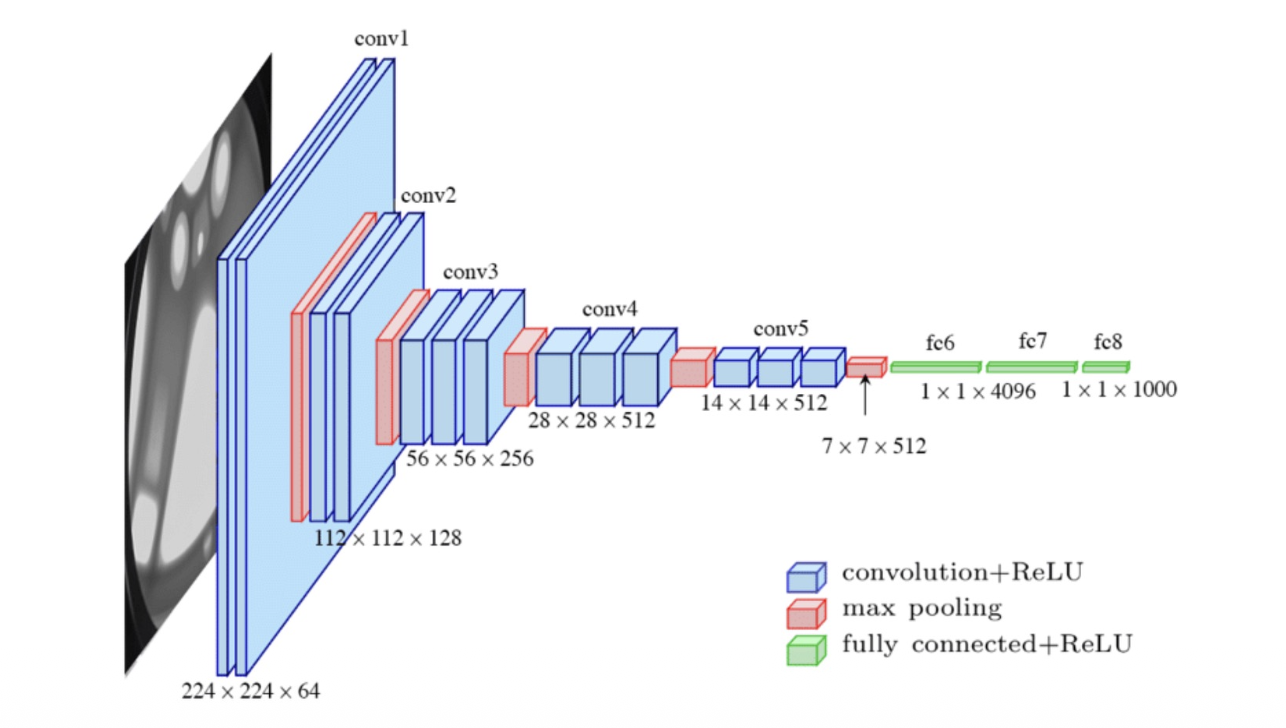
Pooling and Model Properties
Pooling Layers
Pooling downsamples activation maps to make representations smaller and more manageable. It operates over each channel independently.
- Max Pooling: Takes the highest value from the area covered by the kernel (common setting: ).
- Average Pooling: Calculates the average value from the area.
- Output Size: . Note: the depth () remains equal to the input depth ().
Equivariance vs Invariance
- Equivariance: . Convolutions are shift-equivariant, meaning they detect patterns, regardless of their location.
- Invariance: . Pooling and fully connected layers help achieve shift-invariance, allowing the network to generalise (e.g., a cat is still a cat regardless of position).
- Rotation: Standard CNN are not invariant or equivalent with respect to orientation/rotation.