The MLP, also known as a Feed-Forward Net, is described as a “soft perceptron” that utilises gradient descent to learn it parameters.
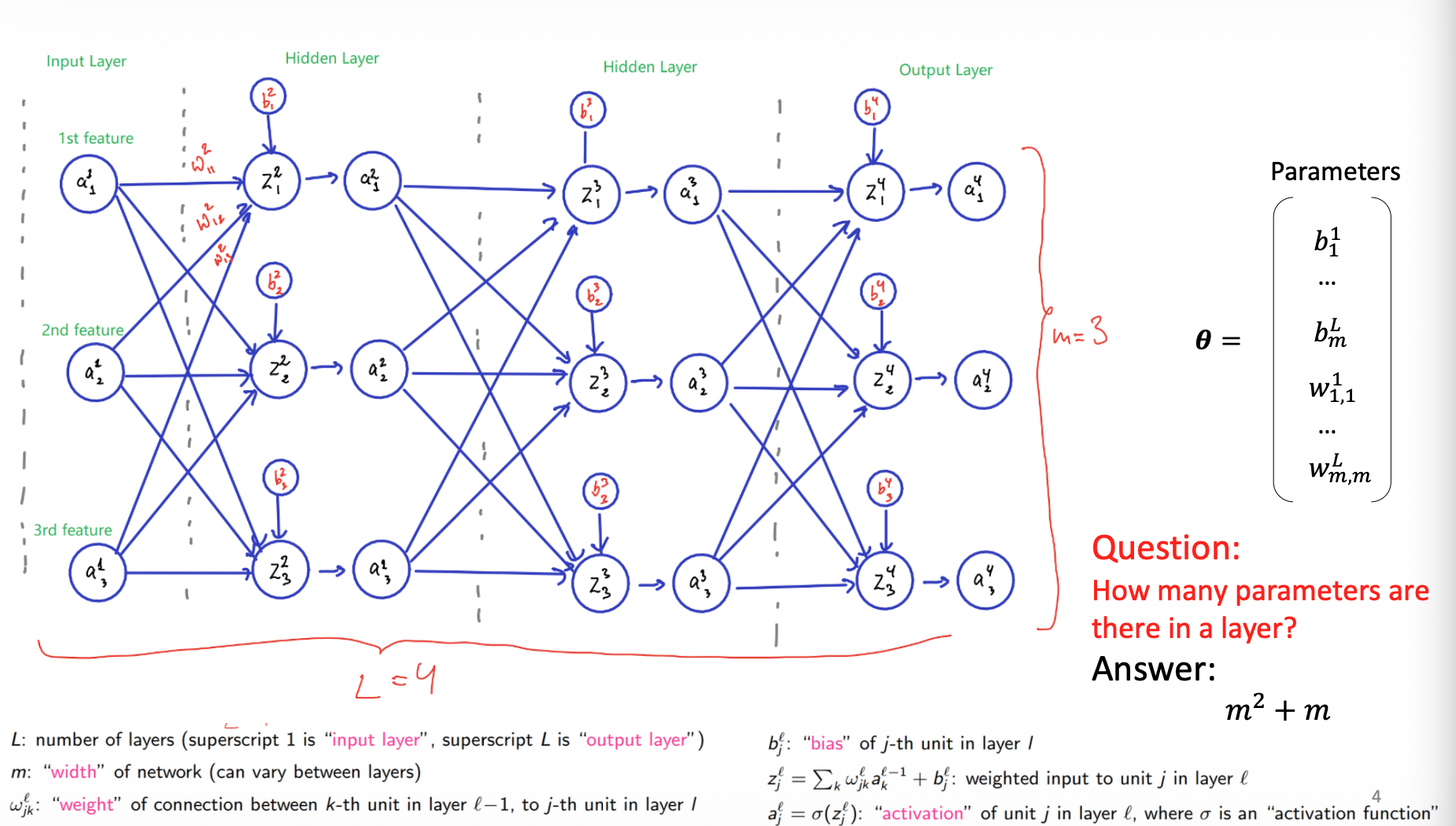
Mathematical Notation
- : Total number of layers. Layer is the input layer, and the superscript denotes the output layer.
- : The width(number of units) of a layer. This can vary between layers.
- : The weight of the connection from the -th unit in layer to the -th unit in layer .
- : The bias of the -th unit in layer
- : The weighted input to unit in layer :
- : The activation of unit in layer : , where is an activation function.
Parameter Calculation
For a layer of width connected to a previous layer of the same width, the total number of parameters (weights + bias) is calculated as .
Activation Functions
The goal is to replace the standard non-differentiable sign function with a different non-linear function to enable gradient-based learning.
- Sigmoid Function:
- Mapping: It maps values from to the range
- Derivative: